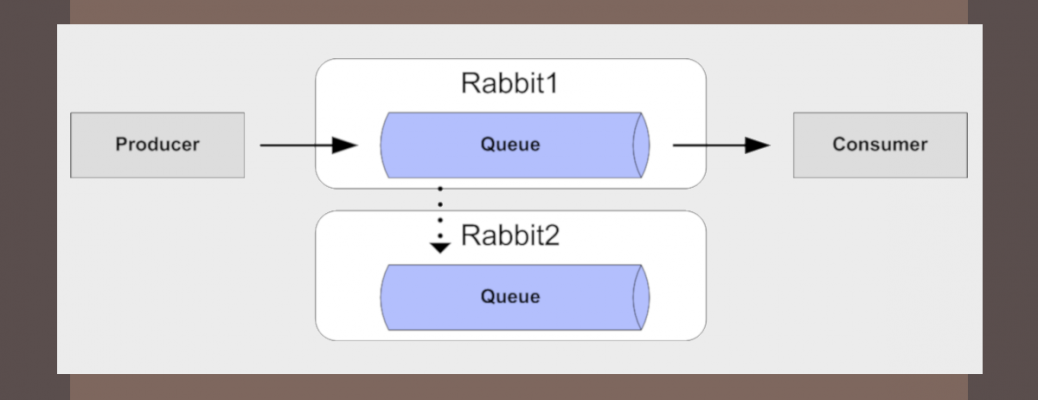
High Availability RabbitMQ With Mirrored Queues
RabbitMQ is a robust message queue which features high message throughput, configurable acknowledgements, an intuitive management GUI and wide client library support. Written in Erlang, RabbitMQ has built a reputation for outstanding stability which makes it a popular choice as a core infrastructure system.
As you plan your overall messaging architecture a universal requirement is to minimize downtime from any single point of failure. Fortunately RabbitMQ comes equipped with built-in high-availability facilities, your tolerance for message loss will determine the which of the available HA options and approaches fits best. This post will mainly focus on setting up RabbitMQ mirrored queues which provide the highest protection against message loss. [Continue reading...] High Availability RabbitMQ With Mirrored Queues

